Brief Introduction
TrajMesa is one of the most important module of our system JUST (JD Urban Spatio-Temporal Data Engine). It aims to manage big trajectory data
efficiently in a convenient way. The framework of TrajMesa is shown as the following figure.
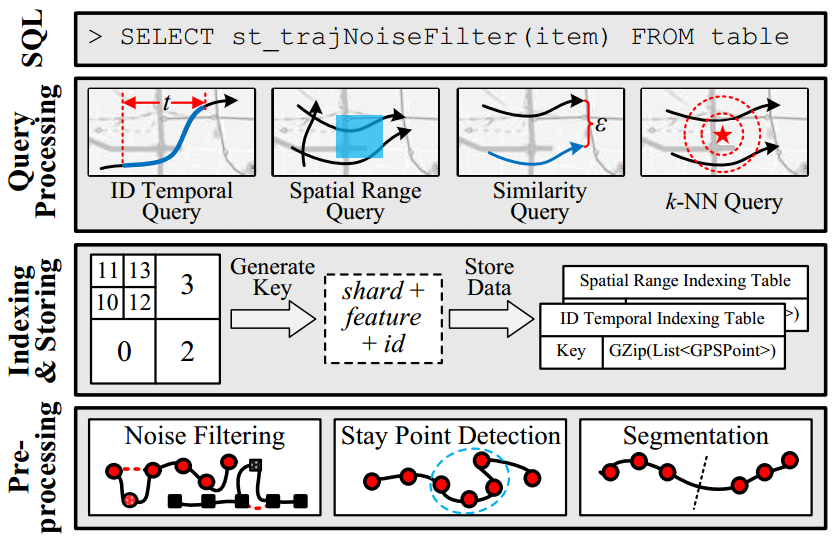
Key Features
(1) Scalability
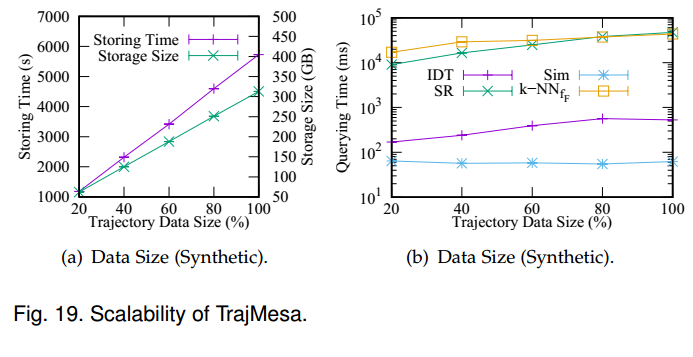
TrajMesa can manage unduly large number of trajectories, but require little for the clusters.
(2) Efficiency
In our experimental settings, TrajMesa is sometimes 100~1000 times faster than the state-of-the-art
in-memory trajectory management system.
(3) Plenty of Queries Support
TrajMesa supports various widely used trajectory queries, including but not limited to:
- ID Temporal Query
- Spatial Range Query
- Similarity Query (for Fréchet distance, Hausdorff distance and DTW distance)
- k-NN Query (k-NN point query and k-NN trajectory query)
- Spatio-Temporal Range Query
- Similarity Temporal Query
- ...
(4) Easy of Use
We design and realize a complete SQL engine, thus all trajectory preprocessing and query processing
functions can be done with a SQL-like statement.
Experiments
Datasets
We use three trajectory datasets to evaluate the performance of TrajMesa.
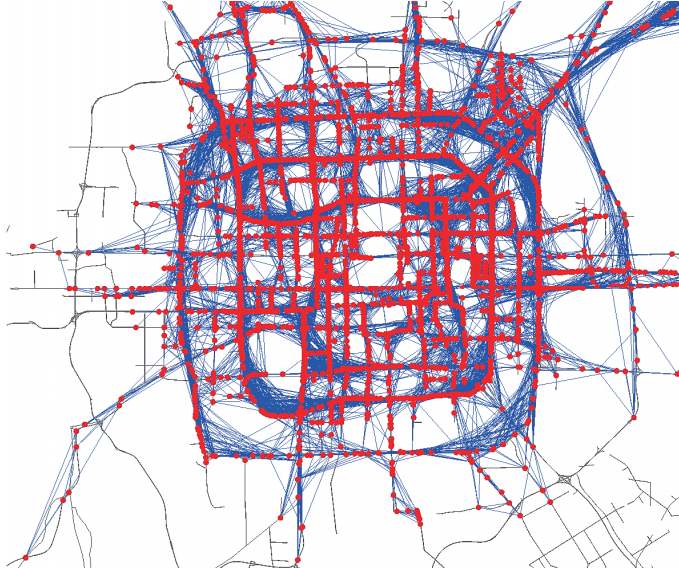
* T-Drive taxi trajectory distribution in Beijing, China
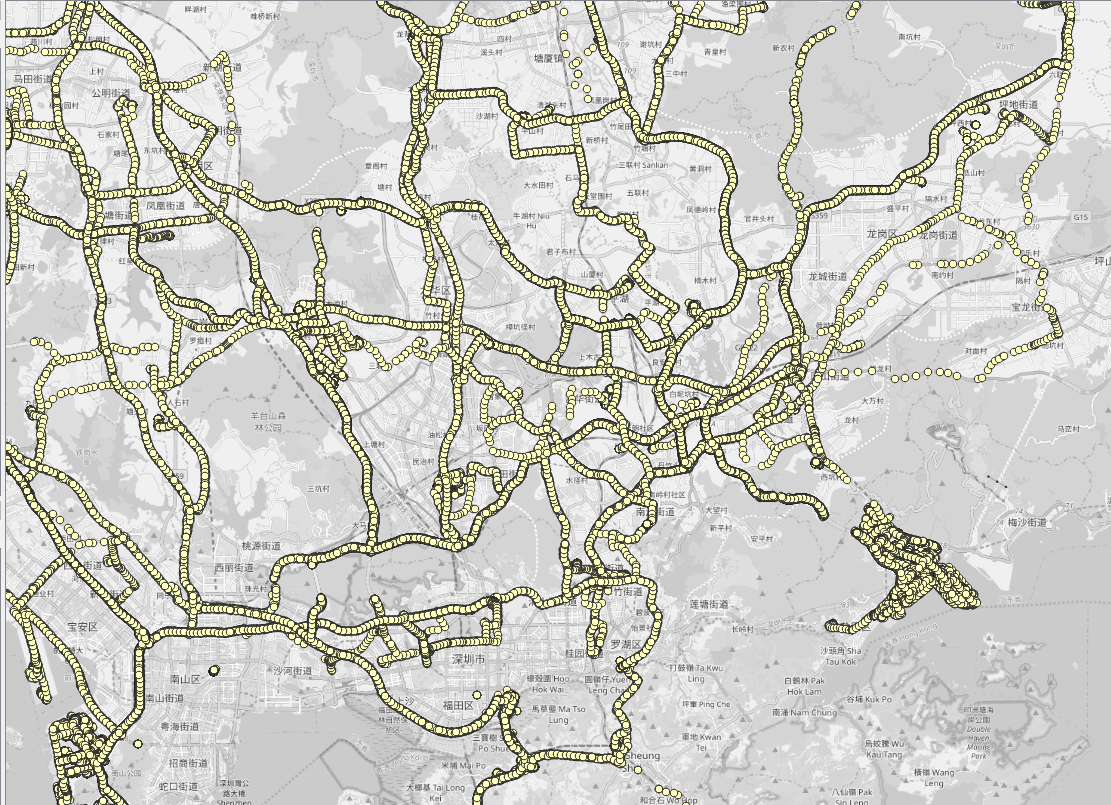
* Lorry trajectory distribution in Guangzhou, China
Results
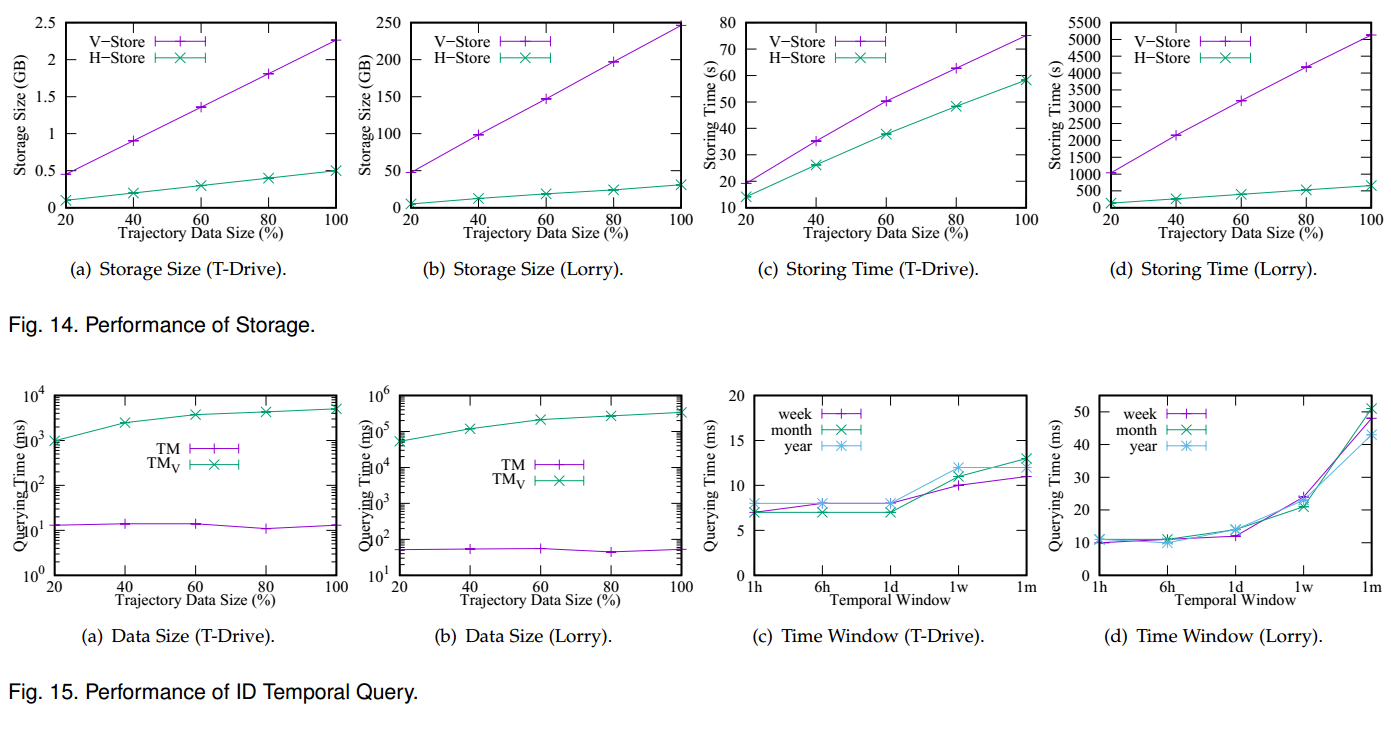
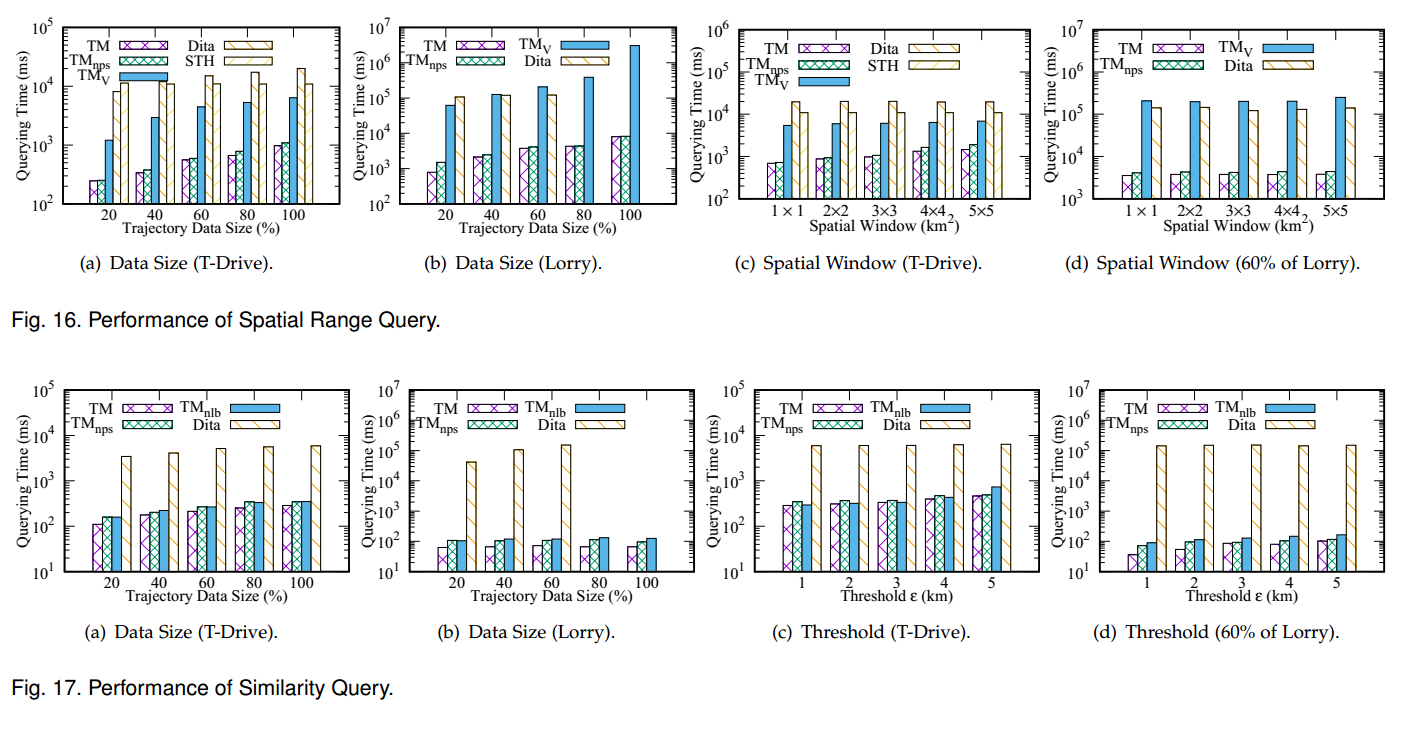
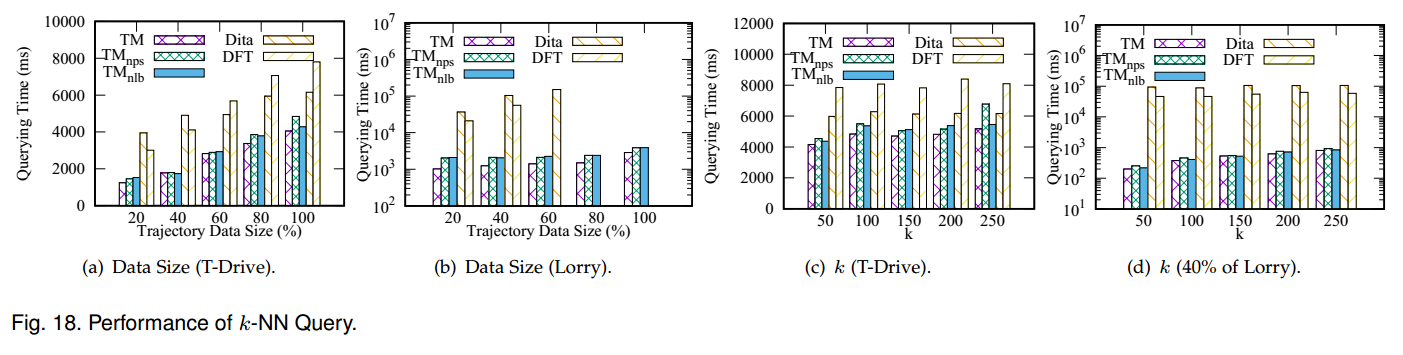
TrajMesa shows a competitive query efficiency with the-state-of-the-art trajectory data management systems
(sometimes even 100~1000 times faster than the in-memory advanced frameworks), and is much more scalable
than them.
Experimental Source Code & Technical Report
System Demostration
We prepare a test account for the reviewers of TKDE. UserName:
JustTestUser, Password:
JustTestUser!1Login
1. Enter the login page: http://portal-just.urban-computing.cn/login
2. Enter the
User Name and Password, then click the button 登录, as
shown in the following picture.
3. The user interface is shown as the following picture, which has four panels:
Table Panel,
View Panel, JustQL Panel, and Result Panel.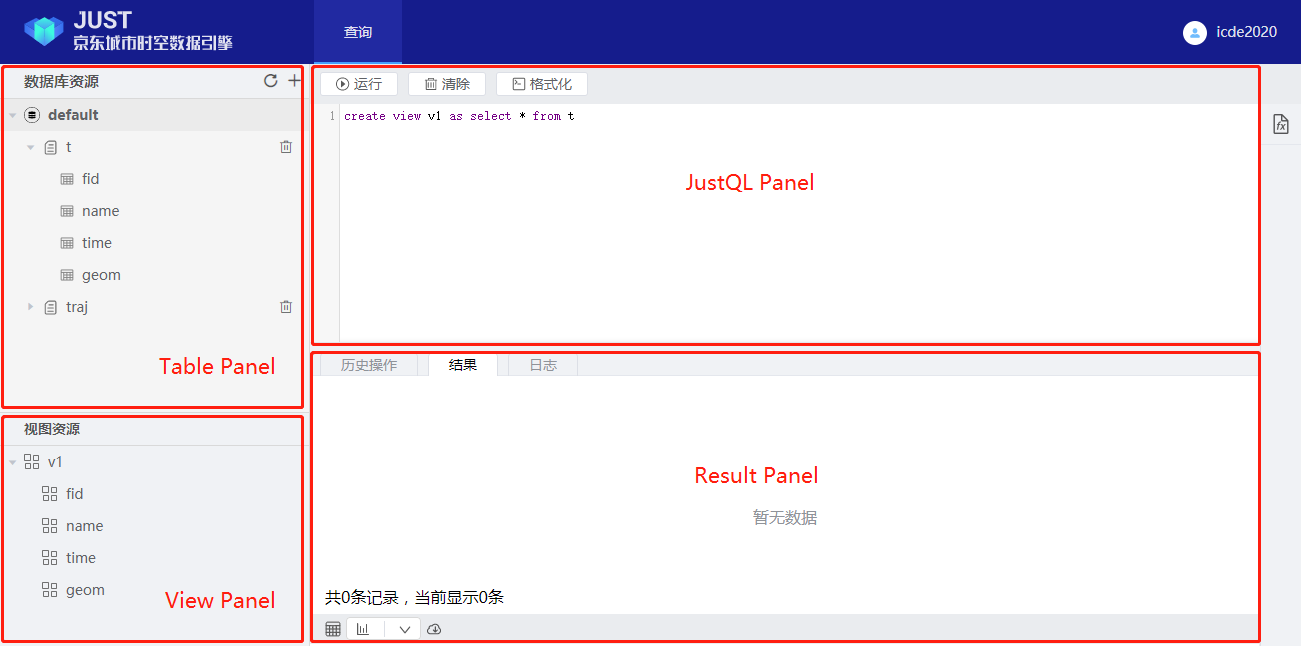
An Example of Trajectory Management
1. Create a table:
create table trajectory_table as trajectory
userdata {
"geomesa.indices.enabled": "xz2,xz2t",
"geomesa.z3.interval": "day",
"geomesa.xz.precision": "16"
}
2. Load data from the HDFS:
LOAD hdfs:'/just_tutorial/trajectory_data' to just:trajectory_table
Config {
oid: "0",
tid:"0",
time: "to_timestamp(3)",
geom: "st_makePoint(1,2)"
} separator ','
3. Spatial range query:
select
*,
item
from
trajectory_table
where
item within st_makeMBR(113.1,23.2,113.5,23.6)
Note that the
item is a implicit field.Users can show the result with a map view.
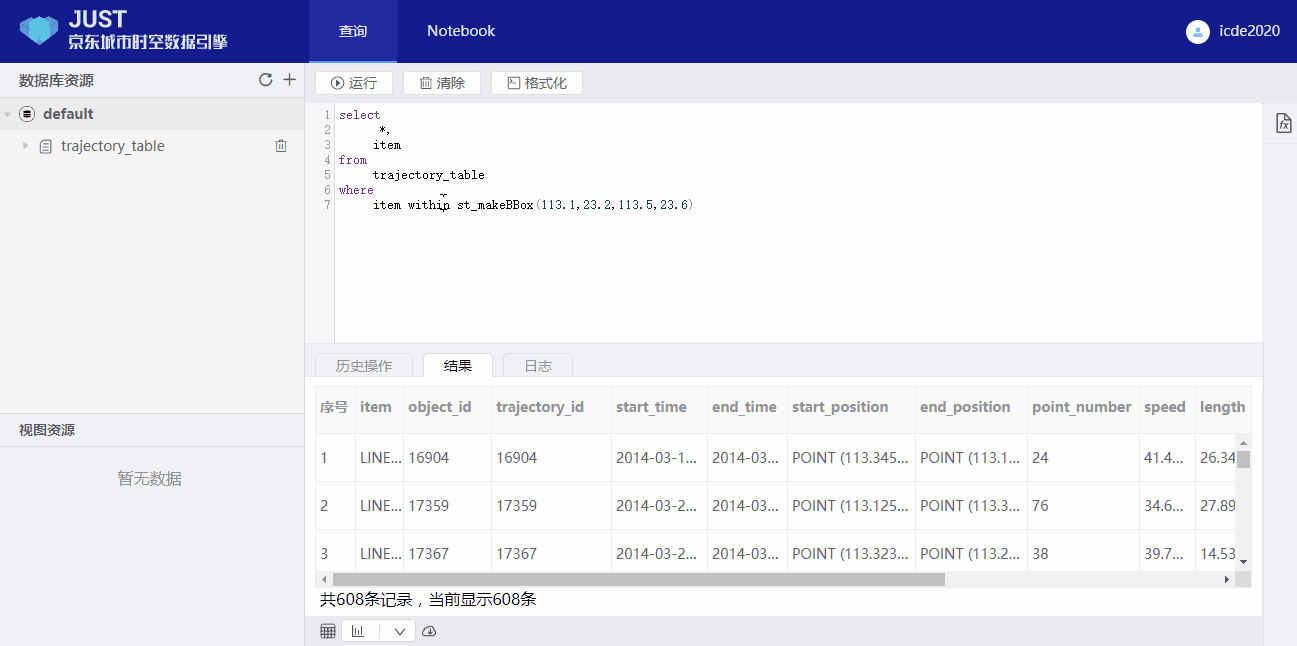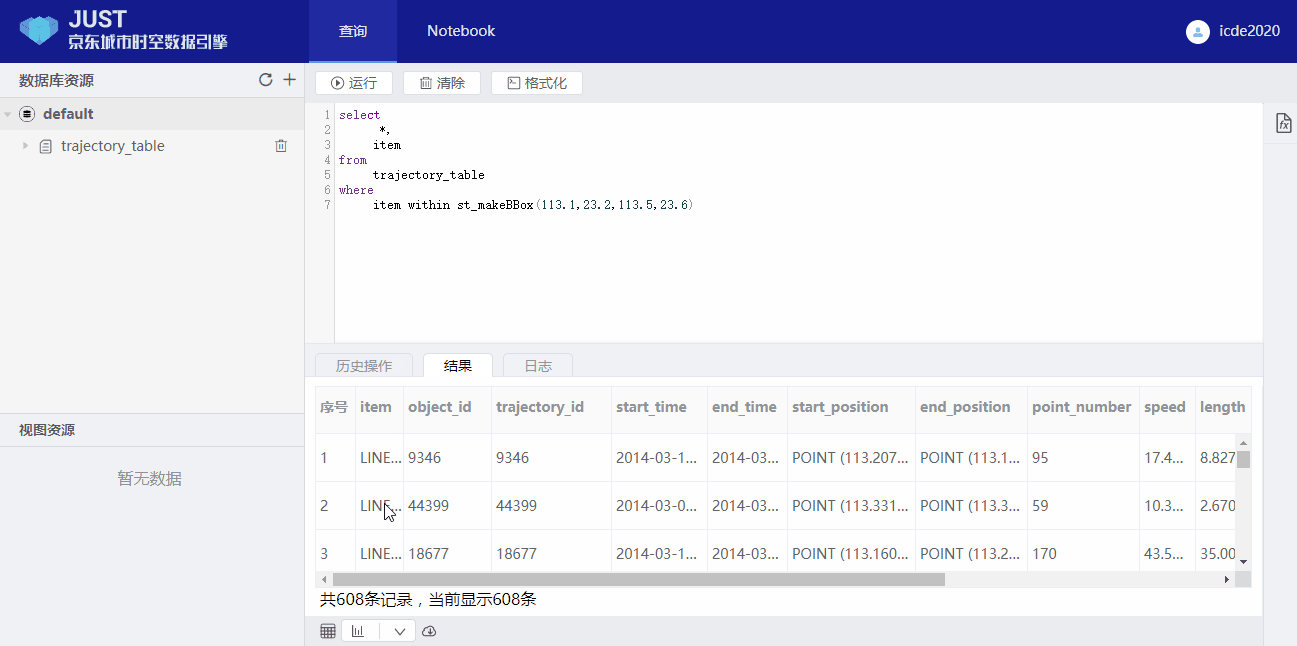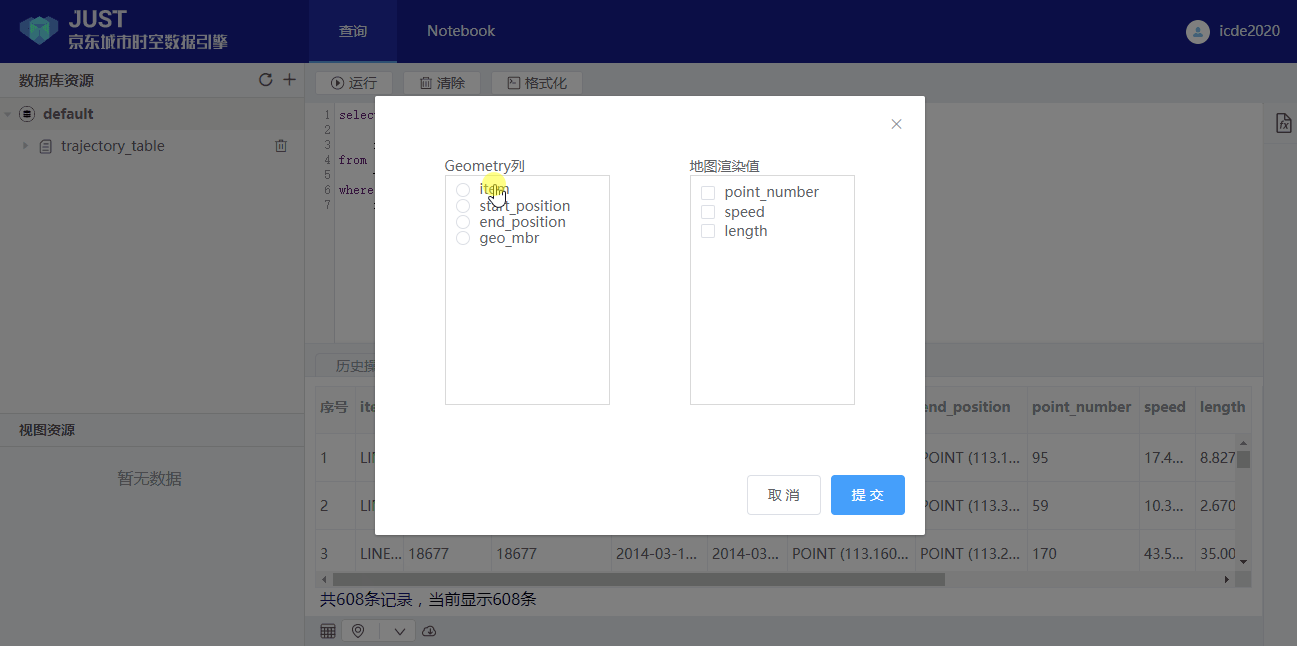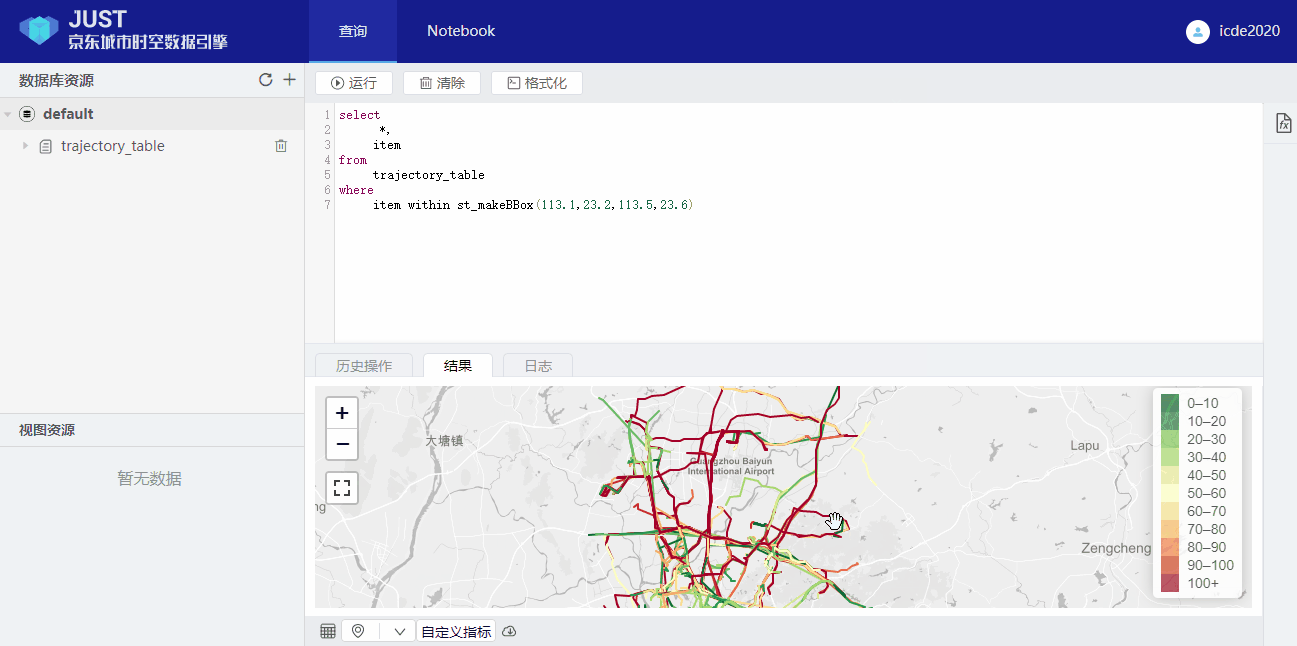
4. Spatial-temporal range query:
select
*,
item
from
trajectory_table
where
item within st_makeMBR(113.1, 23.2, 113.5, 23.6)
and item between '2014-03-01 00:00:00' and '2014-03-15 00:00:00'
5. K-NN point query:
select
*,
item
from
trajectory_table
where
item in st_KNN(st_makePoint(113.84, 22.63), 100)
6. K-NN trajectory query:
select
*,
item
from
trajectory_table
where
item in st_KNN(
st_makeTrajectory(
'LINESTRING (113.780632 22.689121, 113.780281 22.689474, 113.780319 22.690006, 113.780464 22.691366, 113.782349 22.691311)'
),
'frechet',
2)
Now we support three widely used trajectory distance:
frechet, hausdorff, dtw.7. Create a view:
create view trajectory_view as
select
*,
item
from
trajectory_table
where
item within st_makeMBR(113.1, 23.2, 113.5, 23.6)
8. Trajectory noise filter:
SELECT
st_trajNoiseFilter(
item,
{
"@type": "COMPLEX_FILTER",
"maxSpeedMeterPerSecond": 60.0,
"segmenterParams": {
"maxTimeIntervalInMinute": 60,
"maxStayDistInMeter": 100,
"minStayTimeInSecond": 100,
"minTrajLengthInKM": 1,
"segmenterType": "ST_DENSITY_SEGMENTER"
}
}
)
FROM
trajectory_view
Where the second param of
st_trajNoiseFilter is to config
which filter method is used. If omited, we will use the default method.9. Trajectory segmentation:
SELECT
st_trajSegmentation(
item,
{
"maxTimeIntervalInMinute": 10,
"maxStayDistInMeter": 100,
"minStayTimeInSecond": 100,
"minTrajLengthInKM": 2,
"segmenterType": "HYBRID_SEGMENTER"
}
)
FROM
trajectory_view
Where the second param of
st_trajSegmentation is to config
which segmentation method is used. If omited, we will use the default method.10. Trajectory stay point:
SELECT
st_trajStayPoint(
item,
{
"maxStayDistInMeter": 15,
"minStayTimeInSecond": 60,
"stayPointType": "CLASSIC_DETECTOR"
}
)
FROM
trajectory_view
Where the second param of
st_trajStayPoint is to config which
stay point detection method is used. If omited, we will use the default method.11. Store the stay point detection result:
create view stay_point_view as
SELECT
st_trajStayPoint(
item,
{
"maxStayDistInMeter": 15,
"minStayTimeInSecond": 60,
"stayPointType": "CLASSIC_DETECTOR"
}
)
FROM
trajectory_view
store view stay_point_view to table stay_point_table
12. Drop views:
drop view trajectory_view
drop view stay_point_view
13. Drop tables:
drop table trajectory_table
drop table stay_point_table